Interview with Dr. Kikuo MAEKAWA, a new Director-General of the National Institute for Japanese Language and Linguistics (Part 1)

Interview with Dr. Kikuo MAEKAWA,
a new Director-General of the National Institute for Japanese Language and Linguistics
In April 2023, Dr. Kikuo MAEKAWA was appointed as the new Director-General of the National Institute for Japanese Language and Linguistics. In part one of this interview, we asked him about the process leading up to his settling on the research focus of phonetics, and the details of his research from past to present, including the development of various corpora, and speech production study using MRI.
Encounters with “dialect” and “phonetics”
In terms of how I came to settle on phonetics, the difficulties in pronouncing foreign languages played a part. I had been studying French as an undergraduate, but when I entered the doctoral program, I made the decision to abandon French and narrow my research focus to the Japanese language.
I don’t think that French is that difficult of a language for Japanese people as long as its pronunciation is concerned, but I was often corrected by a teacher who was especially strict about pronunciation. And despite my efforts, it just didn’t go well. When I thought seriously about why it was so difficult, I arrived at the question of how we actually produce our speech sounds. I suspect that many people who enter the field of phonetics have a similar journey to recount.
Right about the time I was a graduate student, I was involved in a large national project led by linguist Professor Takeshi SHIBATA. This “Language Standardization” project was a major Grants-in-Aid for Scientific Research (“KAKENHI” hereafter) project. This project included nearly all areas of linguistic research including syntax, analysis of written and spoken language, and phonetics, and within the area of phonetics, there was a theme related to the standardization of dialects.
I was invited to join a research group of dialect scholars led by Professor Motohisa IMAISHI, who was at Tottori University at the time, and I played an interpreter-like role between this group and the research group of Professor Hiroya FUJISAKI at the Faculty of Engineering, the University of Tokyo. The ties I developed with these researchers have led me to this point.
Research at the National Institute for Japanese Language and Linguistics
I started my study of Japanese dialects, looking at things such as syllabic structure, and I continued to focus my research on dialects after joining Tottori University. Five years later, I was hired as a researcher at the Phonetics Laboratory of the National Institute for Japanese Language and Linguistics (“NINJAL” hereafter).
For a long while, phoneticians were making observations of how human speech organs such as the tongue, throat, and lips move when one speaks, but the observation was done by introspection based on the proprioceptive perception of muscles. Put simply, we didn’t know if the observation was really true. Various ways to look at those movements of speech organs objectively were considered, one of which was x-ray film footage. About the time I took up my post at NINJAL, a report titled "Japanese Vowels, Consonants, Syllables: Experimental Phonetics Research of Articulatory Movements" was released. The idea of carrying on this research was considered one possible choice, but the experimental method of having subjects produce sound while being exposed to X-rays carried a risk of exposure, making it impossible to obtain a large amount of data using the same method. Later on, in the 2010s, it became possible to record video footage using magnetic resonance imaging (“MRI” hereafter), and the research of speech production was revived for the first time in three decades.
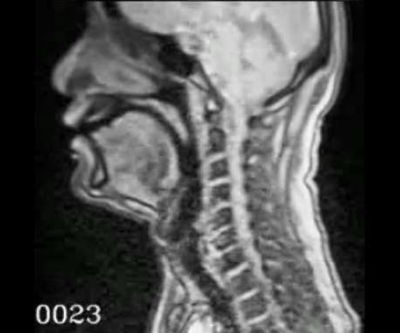
Example of real-time MRI images
From the time I joined NINJAL, I have been given the freedom to pursue an approach of trial and error. At that time, I was interested in the modeling of intonation of some Japanese dialects, and I had a chance to work with Professors Shigeru KIRITANI and Hajime HIROSE of the Research Institute of Logopedics and Phoniatrics (“RILP” hereafter) at the Faculty of Medicine of the University of Tokyo to conduct electromyographic experiments on dialect intonation.
I was also involved in part of a research group comparing the phonetic characteristics of the Japanese spoken by learners of various linguistic backgrounds and was creating a phoneme-balanced speech database of L2 Japanese.
Studying in the United States
In 1993, I got the opportunity to spend 10 months in the United States at the Department of Linguistics of Ohio State University (OSU). Looking back now, I think that my stint abroad had an important impact on my later research. Phonological theory at the time did not have almost any link with phonetic experiments, but the Phonetics Laboratory of OSU led by Professor Mary Beckman was one of the centers of Laboratory Phonology, which sought to combine phonological theory with experimental research. Personally, I’d also always thought this approach was necessary, so I enjoyed taking part in the research. When I returned to Japan, the trend of Laboratory Phonology had also arrived in Japan, so the timing was perfect.
For a while after my return, I conducted research based on Laboratory Phonology-based ideas, and as an extension of this I began to work on “paralinguistic information.” Paralinguistic information refers to the intent behind various utterances, such as suspicion, dismay, disagreement, admiration, and so forth. From around 1997, I began systematic joint research into paralinguistic information with the RILP and NTT Communication Research Laboratory. We did fiberscopic observation of the influence of paralinguistic information on the vocal fold vibration (at RILP) and EMA (an electromagnetic device to record the movement of the tongue)-based observation of the tongue movement (at NTT). We made a host of interesting discoveries. Our research produced quite a lot of feedback, including plenary talks and invited talks at several international conferences, it was at this time that I was suddenly approached by the subject of the Corpus of Spontaneous Japanese (“CSJ” hereafter) came up.

Director-General MAEKAWA (left) and NIHU President KIBE (right) during the interview
The Corpus of Spoken Japanese (CSJ)
The mastermind behind the CSJ was Dr. Seiichi YAMAMOTO (Professor Emeritus of Doshisha University), who was then leading the group of automatic speech translation studies at the ATR (Advanced Telecommunications Research Institute International). Based on the idea that creating a large database for automatic speech recognition study should involve linguistics researchers in addition to IT engineers, a team led by Professor Sadaoki FURUI of Tokyo Institute of Technology (TIT), who passed away last year, was formed. For my part, I’d recognized the need for a database way back from my time as a student and had researched to create a small-scale database of dialect speech on my own, but here was the first time we had the opportunity to create a large-scale database, using as much time and money that was needed. The five-year project ran from 1999 to 2003, and we published the database in April 2004.
The corpus was designed for the study of automatic speech recognition, it was used by many researchers in the field as we released the corpus at various stages of corpus development. Around autumn in the third year of the project, it became possible to train a speech recognition system using that data. Professor Tatsuya KAWAHARA from Kyoto University (KU) also took part in this effort, and when the systems of TIT and KU were each trained separately, both showed dramatic performance improvements.
Personally, I was delighted to see that the corpus was used in many research fields. Moreover, this project was a good experience for NINJAL in that it revealed the potential of large-scale language resource studies conducted by teams of multiple researchers.
The Balanced Corpus of Contemporary Written Japanese (BCCWJ)
Following the release of the CSJ, we ran a one-year corpus study group that not only involved the members of the CSJ but also specialists in the study of written Japanese, and we finally decided to start a new project aiming at the compilation of a balanced corpus of written Japanese. At that time, there was no such corpus. Personally, I had thought there was a need for a corpus of written texts.
Research papers on psycholinguistics are always checked for things like “Why was that word used in the experiment?” or “What was the frequency of that word and is there any bias?” But as we lacked any data to answer these questions, those papers would not survive peer review when submitted to international journals. We could somewhat answer those questions for spoken words with the CSJ, but since there was no balanced corpus of written texts, I heard quite often about how one was sorely needed. This is how we started the project of what is known today as the Balanced Corpus of Contemporary Written Japanese (“BCCWJ” hereafter).
Because NINJAL’s budget was much too small for the construction of the BCCWJ, we ended up obtaining a large research grant from the KAKENHI grant in 2006. The project proceeded successfully, but in 2009, the fourth year of the five-year plan, responsibility for NINJAL was transferred to the National Institutes for the Humanities, and the release of the BCCWJ was slightly delayed. In the autumn of 2010, the following year, “Chunagon” (Corpus Search App. created by NINJAL for the searching of morphological information) was released online, and then in 2011 we finally managed to release a DVD edition of the complete data. This was the busiest time of my life.
Corpus Search App. “Chunagon” (Japanese only)
(Interviewer: Nobuko KIBE, President, National Institutes for the Humanities)
(Text: Go OHBA, Researcher, Center for Innovative Research, National Institutes for the Humanities)
Kikuo MAEKAWA, Director-General, National Institute for Japanese Language and Linguistics specializes in phonetics and language resources. After studying linguistics at the Graduate School of Sophia University, he ended up earning his Ph.D. from the Graduate School of Information Science and Technology, Tokyo Institute of Technology. In 1984 he worked as an assistant in the Faculty of Education of Tottori University, and in 1987 as a lecturer in the same faculty. Since 1989 he has worked at the National Institute for Japanese Language and Linguistics, holding his current position since April 2023.